
What is a data lake?
A data lake is an architectural evolution in the way that the business community views data-sharing. Data has historically been shared on a case-by-case, slow, and manual way while data-lakes allow for standardized, fast, and automated ways of ensuring everyone has the data they need.
How does a data lake work?
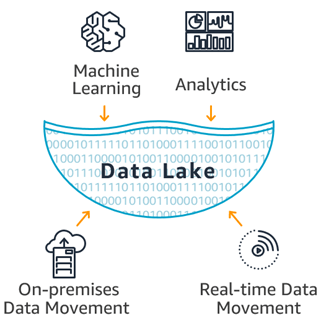
Ingest – Data arrives in any raw format, and is stored for future analysis or disaster recovery. Companies typically segment out several data lakes depending on privacy, production access, as well as the team’s that will be leveraging the incoming information.
Store – Data lakes allow business to manage and organize nearly infinite amounts of information. Cloud object stores (AWS S3, Azure Blob, Google Cloud Storage, etc.) offer high availability access for big data computing, at an extremely low-cost.
Process – With cloud computing, infrastructure is now simply an API call-away. This is when data is taken from its raw state in the data lake and formatted to be used with other information. This data is also often aggregated, joined, or analyzed with advanced algorithms. Then the data is pushed back into the data lake for storage and further consumption by business intelligence or other applications.
Consume – When companies talk about having a self-service data lake, Consume is typically the stage in the life-cycle they are referencing. At this point, data is made available to the business and customers for analytics as their needs require. Depending on the type of complex use cases, end-users may also indirectly or directly be using the data in the form of predictions (forecasting weather, financials, sport performance, etc) or perceptive analytics (recommendation engines, fraud detection, genome sequencing, etc).
What role can data lakes play in CSR, Sustainability, and Culture?
Organizations that successfully generate business value from their data, will outperform their peers. An Aberdeen survey saw organizations who implemented a Data Lake outperforming similar companies by 9% in organic revenue growth. These leaders were able to do new types of analytics like machine learning over new sources like log files, data from click-streams, social media, and internet connected devices stored in the data lake. This helped them to identify, and act upon opportunities for business growth faster by attracting and retaining customers, boosting productivity, proactively maintaining devices, and making informed decisions.
Encast’s Vision On Data Lakes for CSR
At Encast, we see data lakes as a natural evolution of product value propositions within our cloud-based ecosystem. Giving and volunteering, circular economy and supply chain, environmental sustainability, culture and employee engagement – these are all of the moving pieces within the domain of CSR and naturally, the magnitude of data-sharing is unprecedented relative to other corporate functions. While some argue that “data lakes for CSR” will become a category of its own, we have a different view on the future of this space. The giving and volunteering solution of the future, will be data-lake-enabled. The circular economy and supply chain solution of the solution will be data-lake-enabled. The environmental sustainability solution of the future will be data-lake enabled. Even the culture and employee engagement solution of the future will be data-lake-enabled. What does this practically mean? It means that the data-lake itself becomes a decentralized phenomenon that exists within the virtual walls of each company. It also means that departments no longer have to wait on each other to allow for secure data exchanges. This is the future of CSR – a future where data collection, reporting, governance, and even impact evaluation is decentralized.


")
